SUMMARY
↣ Circular Single Linked List
↣ Double Linked List
↣ Circular Double Linked List
➤ Circular Single Linked List
✻ Untuk konsep Circular Single Linked List ini sebenarnya tidak jauh berbeda dengan konsep Single Linked List umum. Perbedaannya ialah dalam konsep circular, node terakhir yang ada dalam memori kita itu menunjuk node pertama kita, dengan kata lain yaitu Head. Untuk konsep Circular Single Linked List ini juga tidak terdapat pointer yang menunjuk ke NULL, karena setiap node akan menunjuk node lainnya.
✲ Untuk kegunaannya sendiri, pada umumnya konsep ini digunakan untuk maintain sistem operasi yang sedang berjalan, atau seperti saat user menjalankan suatu browser dan menuju ke web page lain, lalu user ingin kembali ke web sebelumnya dengan menggunakan tombol back/previous.
➤ Double Linked List
✻ Nah, untuk konsep double linked list, setiap node kita nantinya akan mempunyai 2 pointer yaitu *next dan *prev, berbeda saat kita memakai konsep single linked list yang hanya memiliki pointer *next. Dengan adanya *prev, ini lebih memudahkan kita untuk melakukan searching data, insert maupun delete data kita nantinya karena *prev merupakan pointer yang menunjuk node sebelumnya.
✱ Jadi, dengan konsep double Linked List, kita dapat menuliskan code dengan contoh sebagai berikut:
Node *current = (*Node)malloc(sizeof(Node));
current->data = data;
current->next = NULL;
current->prev = NULL;
return current;
➤ Circural Double Linked List
✲ Nah, untuk konsep yang terakhir ini, yaitu Circural Double Linked List, tidak jauh berbeda dengan konsep Circural Singe Linked List, bedanya dalam konsep ini memiliki 2 pointer. Dan juga untuk konsep ini, seharusnya lebih memudahkan kita dalam memanipulasi data pada pointer dan mengefesiensikan melakukan pencarian data.
Stack
→ Untuk konsep stack dalam linked list sendiri menggunakan konsep yang bernama Last In First Out atau LIFO. Untuk kata 'Last' yang berarti terakhir, 'In' yang berarti masuk, 'First' yang berarti pertama, dan 'Out' yang berarti keluar, maka konsep ini bermakna bahwa barangsiapa yang terakhir masuk, maka dia lah yang keluar. Pada konsep dalam linked list ini, berarti bahwa node yang terakhir kita masukkan, maka node itu lah yang akan pertama kali keluar. Biasanya konsep Stack ini sendiri dapat diartikan dengan analogi tumpukan, atau makna dari kata 'Stack' sendiri yaitu tumpukan.
QUEUE
→ Berbeda dengan konsep Stack (LIFO), konsep QUEUE dapat juga diartikan sebagai konsep 'First In First Out' atau FIFO. Nah, dari kalimatnya sendiri, kita sudah dapat mengetahui bahwa konsep ini berarti node yang masuk terlebih dahulu, maka node itulah yang akan keluar terlebih dahulu. Kalau dianalogikan dalam kehidupan sehari-hari, dari kata Queue sendiri yaitu antrian, maka kita dapat analogikan sebagai ada orang yang sedang mengantri untuk keluar dari ruangan. Orang yang paling pertama mengantri, maka orang itulah yang akan keluar / mendapatkan apa yang ia mau terlebih dahulu.
- Before
- After
Hashing (Hash Table) & Binary Tree
✲ Hash Table
Nah, untuk sesi blog kali ini, kita masih akan membahas tentang Struktur Data yaitu Hash Table. Hash Table adalah suatu struktur data yang berupa tabel, dimana nantinya tiap di dalam tabel tersebut terdapat sebuah tempat-tempat untuk menyimpan data-data. Tempat-tempat tersebut kita analogikan sebagai loker, yang dimana tiap loker memiliki index lokernya dan kunci lokernya dan didalam lokernya terdapat data-data yang kita simpan atau biasanya disebut juga value.
✽ Hashing Function
Jika kalian lihat gambar diatas, dapat dilihat bahwa "John Smith" , "Lisa Smith" merupakan kunci loker nya atau (Keys). Nah dengan kunci tersebut, kita dapat mengetahui index dari loker tersebut, dan didalam loker tersebut terdapat data-data yang kita simpan sesuai dengan lokernya. Nah, untuk mendapatkan index loker dari kunci yang kita punya, kita dapat menggunakan suatu metode yaitu Hash Function. Hash Function ini adalah proses atau metode untuk mendapatkan index dengan cara mengubah kunci yang kita punya menjadi yang namanya Hash Value. Hash value inilah yang nantinya dipakai sebagai index dari tempat untuk penyimpanan data kita. Jadi, dengan kata lain, Hash Function : Hash Key diubah menjadi -> Hash Value. Nah, pasti kalian bertanya-tanya nih, hash function itu cara pakainya gimana. Untuk hash function sendiri, banyak sekali caranya, dan biasanya itu menggunakan komputasi matematika. Bagaimana kalau nanti dalam proses hash function, kita mendapatkan hash value yang padahal hash value tersebut sudah terdapat data yang diisi sebelumnya? Nah, hal ini dinamakan sebagai Collision. Jadi, Collision itu intinya, saat kita melakukan hashing, kita mendapatkan loker yang sudah ada isinya, jadi cara solvenya bagaimana? Cara solve Collision itu ada banyak, diantaranya adalah:
- Separate Chaining (Open Hashing)
Jadi, dalam metode Separate Chaining ini, jika kita mendapatkan suatu hash value yang sudah ada sebelumnya setelah melakukan hash function, data yang baru ingin kita insert ini kita sambung dengan data yang sebelumnya dengan menggunakan linked list. Jadi data pertama akan memegang alamat data kedua, dan begitu seterusnya sehingga kita tetap dapat melakukan insert dan pembacaan data.
- Linear Probing
Nah untuk cara berikutnya yaitu Linear Probing, berbeda dengan chaining, cara ini tidak menggunakan linked list. Dengan metode ini, untuk solve collision yang ada adalah dengan memasukkan data yang kita punya ke index array selanjutnya. Seperti pada gambar di atas, Code Monk sudah terdapat di index ke 2. Namun setelah melakukan hash function terhadap "Hashing", ternyata hash value yang didapatkan juga index 2, makanya "Hashing" tersebut dipindahkan ke index berikutnya yaitu index ke 3.
✲
Hashing in BlockChain
Seperti yang kita ketahui, blockchain menggunakan metode yang dinamakan cryptography untuk melindungi dan mengamankan data-data yang dipunyai oleh mereka. Manfaat yang dimiliki cryptography dalam blockchain ini cukup banyak, selain melindungi transaksi yang terjadi, juga melindungi mata uang digital yang disimpan. Nah, cryptography ini digunakan sebagai hashing untuk menandakan setiap2 blok yang ada agar menjadi unik. Penanda hash tersebut untuk melindungi data-data yang ada.
✻
Binary Tree
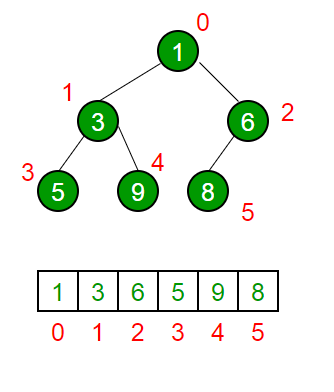
Binary Tree adalah konsep struktur data yang berbentuk seperti pohon yang dapat saling berhubungan dan terdiri dari 1 akar utama dan memiliki maksimal 2 child yang biasanya nanti disebut dengan left dan right. Sebenarnya, terdapat banyak sekali jenis binary tree, diantaranya adalah binary search tree, red black tree, AVL tree (Balanced Tree), Skewed Tree.
Binary Search Tree
--> Binary Search Tree adalah konsep struktur data yang berbentuk seperti pohon yang dapat saling berhubungan dan terdiri dari 1 akar utama dan memiliki maksimal 2 child yang biasanya nanti disebut dengan left dan right. Nah untuk konsep dari binary search Tree sendiri, jikalau node yang ingin baru dimasukkan valuenya lebih besar dari rootnya, maka dia akan masuk ke kanan rootnya, jikalau valuenya lebih kecil, maka node nya akan masuk ke kiri rootnya. Begitu terus sampai semua node yang diinginkan telah dimasukkan. Bagian node-node paling bawah dari BST disebut juga leaf.
Keuntungan dalam menggunakan binary search tree adalah kita dapat melakukan searching, insertion, dan deletion suatu node / data yang diinginkan dengan mudah karena semua node sudah tersusun dengan rapi dan terstruktur sehingga memudahkan para programmer.
https://www.hackerearth.com/practice/data-structures/hash-tables/basics-of-hash-tables/tutorial/
https://www.programiz.com/dsa/hash-table